Designing One Big Table (OBT)
Not a Medium member? No problem. Read free here.
Introduction
But, but but, one big table (OBT) can’t handle hierarchies! Yeah, I’ve said that. You’re going to screw up your DW. Others have said that. Kimball modeling is dead, OBT is revolutionizing the modern data stack. Medium articles have been saying this more and more. How can everyone be so wrong about OBT, and yet, be so right at the same time?
Let’s start with a short story. I recently wrote this rebuttal to an article claiming OBT’s dominance in modern data warehousing. Shortly after posting, Karma, being what it is, brought me a project where OBT was a requirement. Funny how that works. No problem. I love a challenge, so I dug into OBT design. I Googled, searched Reddit, posted on Reddit, posted on LinkedIn, and everything came back the same. There is no canonical definition of OBT and most everyone has their own ideas on what OBT is.
We often argue about OBT without realizing the other side is talking about something completely different. The only commonality is we have one big table and we want to make querying easier for downstream consumers. So, let’s stop arguing about OBT, and let’s dig into common implementations and use cases. Focus ourselves on something useful.
Let’s Look at Some Data
Imagine a counseling office. They have customers and three distinct processes to track, onboarding, visits and billing. There is a hierarchy of processes all falling under customers. This case is simple, with only two levels of hierarchy, but the principles we cover will not change due to the number of levels.
Note: If you haven’t watched Modern Family, please know these email addresses are appropriate and funny (at least to me).

This looks like a common way to store the data.
Defining Types of OBT
With no canonical definitions for OBT, it is useful to define the common types and the progressions of design. Below, we will see implementations that grow in utility and complexity. Think about use cases each type would solve for your consumers. Would they help? Or would they cause more confusion?
Type 0 — Multiple Denormalized Fact tables (Many OBTs)
This one is simple. Take a single-grain fact table and replace foreign keys with dimensional columns. This is the most common type of OBT and it reduces the need to join with dimensional tables.

What it Gives Us
- Easily query facts with included dimensional attributes.
Problems?
- None, really. Most of us probably do this somewhere in a reporting layer.
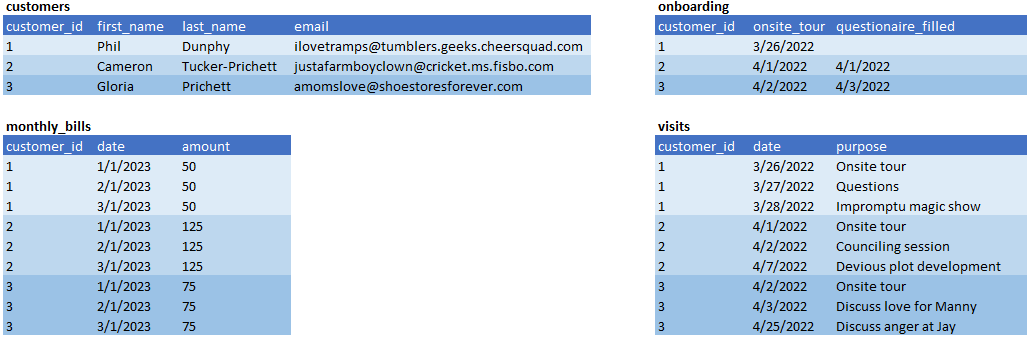
Type 1 — Hierarchical OBT
Type 1, shows a common approach to building a single OBT with multiple grains. We do so using a hierarchy that represents entities and business processes. Looking at the results, a few rules become intuitive.

- 1-to-1 relationships add columns, but no rows (See onboarding).
- 1-to-* relationships add columns and rows (See billing and visits).
- Each row only fills its parent id and the columns needed for the specific grain of the row. This creates a sparsely filled table.
- The rows representing the top of the hierarchy are treated like SCD type-1 dimensions. We show the current value of fist_name, last_name and email.
- Every other row is treated like a fact. It is probably append-only.
What it gives us?
This is my least-favorite level of OBT. We get all customer information in a single table. Go us! At the same time, we make it more difficult to query than the original dimensional models. That being said, we can:
- Query billing, onboarding and vists by customer_id.
- We can easily sum or count the various facts by grouping on customer_id.
- Create this model easily.
- Backfill easily. Since we don’t have a lot of logic, backfilling is simple.
- I’m thinking. I’m thinking, … I think that’s it.
Problems?
- Distinct needed, just to find the number of customers.
- Self join or window functions needed to include dimensional fields like email in queries involving billing or visits.
- No change tracking. What happens if Cameron changes his last name? We will know the current name, but will not know what it used to be. This could be a problem for downstream consumers.
Type 2 — Hierarchy Levels
Type 2 is where hierarchical OBT starts being useful. It includes all the features of level 0, but adds in hierarchy levels. Each hierarchy level represents where in the business hierarchy a row fits into. This can simplify queries a lot.
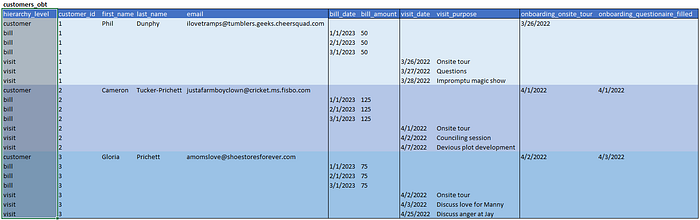
What we get
- Everything in Type 1
- Ability to easily query at the customer level.
- Ability to easily query at the bill and visit levels. (Simple where clause instead of hunting for null values.)
Problems
- ̶D̶i̶s̶t̶i̶n̶c̶t̶ ̶n̶e̶e̶d̶e̶d̶,̶ ̶j̶u̶st̶ ̶t̶o̶ ̶f̶i̶n̶d̶ ̶t̶h̶e̶ ̶n̶u̶m̶b̶e̶r̶ ̶o̶f̶ ̶c̶u̶s̶t̶o̶m̶e̶r̶s̶.̶
- Self join or window functions needed to include dimensional fields like email in queries involving billing or visits.
- No change tracking for dimensional attributes. What happens if Cameron changes his last name? We will know the current name, but will not know what it used to be. This could be a problem in downstream applications.
Type 2 — Added Measures
Type 2 is really getting useful. To negate the need for complex SQL in aggregations, we add common aggregations at the customer level of the hierarchy. In the image below, we added total billed and total visits. Imagine adding measures for things month over month, last thirty days, last ninety, year to date, etc. If these are common queries, we can calculate them once per day and simplify things for downstream consumers.
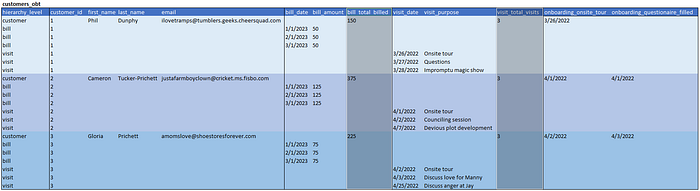
What we get
- Everything in Type 1
- Common aggregation queries with a simple where clause (select email, bill_total_billed from customers_obt where customer_id = 1)
Problems
- D̶i̶s̶t̶i̶n̶c̶t̶ ̶n̶e̶e̶d̶e̶d̶,̶ ̶j̶u̶st̶ ̶t̶o̶ ̶f̶i̶n̶d̶ ̶t̶h̶e̶ ̶n̶u̶m̶b̶e̶r̶ ̶o̶f̶ ̶c̶u̶s̶t̶o̶m̶e̶r̶s̶.̶
- Self join or window functions needed to include dimensional fields like email in queries involving billing or visits. (Solved for common aggregations like total, L7, L30, YTD, etc.)
- No change tracking for dimensional attributes. What happens if Cameron changes his last name? We will know the current name, but will not know what it used to be. This could be a problem in downstream applications.
Type 3 — Cascading
With type 3, we cascade all dimensional attributes from the parent hierarchy down to all hierarchy levels. This makes many queries much easier. If we want dimensional attributes like name or email at the visit grain, we have it. While doing this might seem obvious, it adds a lot of complexity in maintaining the table. We may choose to cascade measures as well.
There are two primary decisions to be made here. First, do we update dimensional attributes on child rows when the values change in the parent row? If we do, we lose change tracking. Let’s say Cam Tucker-Prichett changes his last name to Tucker. How will downstream consumers interpret that when looking at visits?
Second, do we cascade measures like total visits and total billed? This makes it simple to get all monthly bills for customers with more than ten visits. The challenge with both questions is the need to treat every row in the table like a type-1 SCD. It is a tradeoff between engineering complexity and ease-of-use for the consumer.
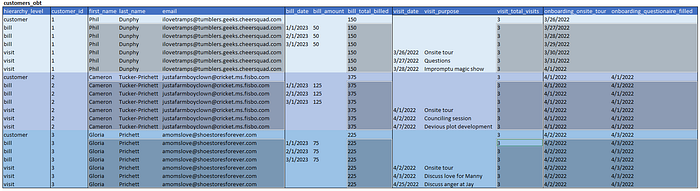
What we get
- Everything in type 2
- Easily query across facts. (Get billing history for all customers who visited more than 10 times. Get name, email and last visit date for all customers who have not completed onboarding.)
Problems?
- D̶i̶s̶t̶i̶n̶c̶t̶ ̶n̶e̶e̶d̶e̶d̶,̶ ̶j̶u̶st̶ ̶t̶o̶ ̶f̶i̶n̶d̶ ̶t̶h̶e̶ ̶n̶u̶m̶b̶e̶r̶ ̶o̶f̶ ̶c̶u̶s̶t̶o̶m̶e̶r̶s̶.̶
- ̶̶S̶e̶l̶f̶ ̶j̶o̶i̶n̶ ̶o̶r̶ ̶w̶i̶n̶d̶o̶w̶ ̶f̶u̶n̶c̶t̶i̶o̶n̶s̶ ̶n̶e̶e̶d̶e̶d̶ ̶t̶o̶ ̶i̶n̶c̶l̶u̶d̶e̶ ̶d̶i̶m̶e̶n̶s̶i̶o̶n̶a̶l̶ ̶f̶i̶e̶l̶d̶s̶ ̶l̶i̶k̶e̶ ̶e̶m̶a̶i̶l̶ ̶i̶n̶ ̶q̶u̶e̶r̶i̶e̶s̶ ̶i̶n̶v̶o̶l̶v̶i̶n̶g̶ ̶b̶i̶l̶l̶i̶n̶g̶ ̶o̶r̶ ̶v̶i̶s̶i̶t̶s̶.̶ ̶(̶S̶o̶l̶v̶e̶d̶ ̶f̶o̶r̶ ̶c̶o̶m̶m̶o̶n̶ ̶a̶g̶g̶r̶e̶g̶a̶t̶i̶o̶n̶s̶ ̶l̶i̶k̶e̶ ̶t̶o̶t̶a̶l̶,̶ ̶L̶7̶,̶ ̶L̶3̶0̶,̶ ̶Y̶T̶D̶,̶ ̶e̶t̶c̶.̶t̶ ̶t̶o̶ ̶f̶i̶n̶d̶ ̶t̶h̶e̶ ̶n̶u̶m̶b̶e̶r̶ ̶o̶f̶ ̶c̶u̶s̶t̶o̶m̶e̶r̶s̶.̶
- ̶̶̶N̶̶̶o̶̶̶ ̶̶̶c̶̶̶h̶̶̶a̶̶̶n̶̶̶g̶̶̶e̶̶̶ ̶̶̶t̶̶̶r̶̶̶a̶̶̶c̶̶̶k̶̶̶i̶̶̶n̶̶̶g̶̶̶ ̶f̶o̶r̶ ̶d̶i̶m̶e̶n̶s̶i̶o̶n̶a̶l̶ ̶a̶t̶t̶r̶i̶b̶u̶t̶e̶s̶.̶̶̶ ̶̶̶W̶̶̶h̶̶̶a̶̶̶t̶̶̶ ̶̶̶h̶̶̶a̶̶̶p̶̶̶p̶̶̶e̶̶̶n̶̶̶s̶̶̶ ̶̶̶i̶̶̶f̶̶̶ ̶̶̶C̶̶̶a̶̶̶m̶̶̶e̶̶̶r̶̶̶o̶̶̶n̶̶̶ ̶̶̶c̶̶̶h̶̶̶a̶̶̶n̶̶̶g̶̶̶e̶̶̶s̶̶̶ ̶̶̶h̶̶̶i̶̶̶s̶̶̶ ̶̶̶l̶̶̶a̶̶̶s̶̶̶t̶̶̶ ̶̶̶n̶̶̶a̶̶̶m̶̶̶e̶̶̶?̶̶̶ ̶̶̶W̶̶̶e̶̶̶ ̶̶̶w̶̶̶i̶̶̶l̶̶̶l̶̶̶ ̶̶̶k̶̶̶n̶̶̶o̶̶̶w̶̶̶ ̶̶̶t̶̶̶h̶̶̶e̶̶̶ ̶̶̶c̶̶̶u̶̶̶r̶̶̶r̶̶̶e̶̶̶n̶̶̶t̶̶̶ ̶̶̶n̶̶̶a̶̶̶m̶̶̶e̶̶̶,̶̶̶ ̶̶̶b̶̶̶u̶̶̶t̶̶̶ ̶̶̶w̶̶̶i̶̶̶l̶̶̶l̶̶̶ ̶̶̶n̶̶̶o̶̶̶t̶̶̶ ̶̶̶k̶̶̶n̶̶̶o̶̶̶w̶̶̶ ̶̶̶w̶̶̶h̶̶̶a̶̶̶t̶̶̶ ̶̶̶i̶̶̶t̶̶̶ ̶̶̶u̶̶̶s̶̶̶e̶̶̶d̶̶̶ ̶̶̶t̶̶̶o̶̶̶ ̶̶̶b̶̶̶e̶̶̶.̶̶̶ ̶̶̶T̶̶̶h̶̶̶i̶̶̶s̶̶̶ ̶̶̶c̶̶̶o̶̶̶u̶̶̶l̶̶̶d̶̶̶ ̶̶̶b̶̶̶e̶̶̶ ̶̶̶a̶̶̶ ̶̶̶p̶̶̶r̶̶̶o̶̶̶b̶̶̶l̶̶̶e̶̶̶m̶̶̶ ̶̶̶i̶̶̶n̶̶̶ ̶̶̶d̶̶̶o̶̶̶w̶̶̶n̶̶̶s̶̶̶t̶̶̶r̶̶̶e̶̶̶a̶̶̶m̶̶̶ ̶̶̶a̶̶̶p̶̶̶p̶̶̶l̶̶̶i̶̶̶c̶̶̶a̶̶̶t̶̶̶i̶̶̶o̶̶̶n̶̶̶s̶̶̶.̶̶̶ If we do not update child rows when the parent row changes.
- Table maintenance complexity can increase exponentially. In some scenarios, all rows behave like type-1 SCD records.
- Backfill can be much more complex. (See above.)
Wrapping it Up
Arguing about OBT will get us nowhere. Instead, let’s focus ourselves on defining patterns and solutions to get the most out of them. We discussed four types of OBT along with their pros and cons. More work needs to be done for types 1–3 to agree on canonical definitions, but we can get there. For now, let’s agree that OBT is one big a$$ table.
Addendum 1
If you want to know where my twisted mind goes whenever I hear “One Big Table,” here you go.
Addendum 2
I am very much interested in working with our community to create canonical definitions for OBT. Furthermore, we should come up with best methods and patterns for maintaining OBT architecture. Please leave your thoughts in the comments, or better yet, share your own articles.
